Tensorflow,Pytorch,PaddlePaddle等等深度学习框架,在介绍框架的时候都会提及到动态图和静态图。其实动态图和静态图都属于计算图,本文就来讲讲什么是动态图和静态图。
计算图
不论是动态图还是静态图,它们都属于计算图。计算图是用来描述运算的有向无环图,它有两个主要元素:
- 结点(Node)
- 结点表示数据,如向量、矩阵、张量。
- 边(Edge)
- 边表示运算,如加、减、乘、除、卷积等。
采用计算图来描述运算的好处不仅是让运算流的表达更加简洁清晰,还有一个更重要的原因是方便求导计算梯度。
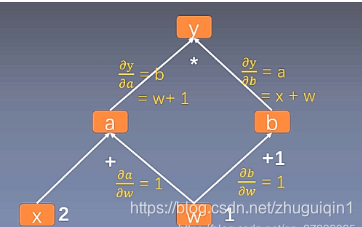
上图表示的是$ y = (w + x) * (w + 1)$代表的计算图,若要计算$y$对$w$的导数,那么结合链式求导法则,就在计算图中反向从y找到所有到w的路径每条路径上各段的导数相乘就是该路径的偏导,最后再将所有路径获得的偏导求和即可。
叶子节点是用户创建的变量,如上图的$x$与$w$,在Pytorch的实现中,为了节省内存,在梯度反向传播结束后,非叶子节点的梯度都会被释放掉。
动态图
动态图意味着计算图的构建和计算同时发生(define by run)。这种机制由于能够实时得到中间结果的值,使得调试更加容易,同时我们将大脑中的想法转化为代码方案也变得更加容易,对于编程实现来说更友好。Pytorch使用的就是动态图机制,因此它更易上手,风格更加pythonic,大受科研人员的喜爱。
静态图
静态图则意味着计算图的构建和实际计算是分开(define and run)的。在静态图中,会事先了解和定义好整个运算流,这样之后再次运行的时候就不再需要重新构建计算图了(可理解为编译),因此速度会比动态图更快,从性能上来说更加高效,但这也意味着你所期望的程序与编译器实际执行之间存在着更多的代沟,代码中的错误将难以发现,无法像动态图一样随时拿到中间计算结果。Tensorflow默认使用的是静态图机制,这也是其名称的由来,先定义好整个计算流(flow),然后再对数据(tensor)进行计算。
动态图 vs 静态图
通过一个例子来对比下动态图和静态图机制在编程实现上的差异,分别基于Pytorch和Tensorflow实现,先来看看Pytorch的动态图机制:
import torch
first_counter=torch.Tensor([0])
second_counter=torch.Tensor([10])
while(first_counter < second_counter)
first_counter+=2
second_counter+=1
print(first_counter)
print(second_counter)
程序执行结果:
tensor([20.])
tensor([20.])
以看到,这与普通的Python编程无异。
再来看看在基于Tensorflow的静态图机制下是如何实现上述程序的:
import tensorflow as tf
first_counter = tf.constant(0)
second_counter = tf.constant(10)
def cond(first_counter,second_conter,*args):
return first_counter<second_counter
def body(first_counter,second_conter):
first_counter = tf.add(first_counter,2)
second_conter = tf.add(second_counter,1)
return first_counter, second_counter
c1,c2 = tf.while_loop(cond,body,[first_counter,second_counter])
with tf.compat.v1.Session() as sess:
counter_1_res, counter_2_res = sess.run([c1,c2])
print(counter_1_res,counter_2_res)
这段代码对应的是TensorFlow1.x版本的,程序在with tf.compat.v1.Session() as sess:之前都是定义计算图,定义了数据和操作步骤,在执行过程中实际上是没有值的,实际上在sess.run之后才有真正计算出了结果。
(⊙o⊙)… 对Tensorflow不熟悉的童鞋来说,第一反应可能会是:这什么鬼!?确实,看上去会有点难受。。。
Tensorflow在静态图的模式下,每次运算使用的计算图都是同一个,因此不能直接使用 Python 的 while 循环语句,而是要使用其内置的辅助函数 tf.while_loop,而且还要tf.Session().run()之类的乱七八糟..
而Pytorch是动态图的模式,每次运算会构建新的计算图,在编程实现上不需要额外的学习成本(当然首先你得会Python)。
动静结合
在最近开源的框架MegEngine中,集成了两种图模式,并且可以进行相互切换,下面举例说明将动态图转换为静态图编译过程中进行的内存和计算优化:
$y = w*x + b$的动态计算图如下:

可以看到,中间的运算结果是被保留下来的,如p=w*x,这样就一共需要5个变量的存储空间。若切换为静态图,由于事先了解了整个计算流,因此可以让y复用p的内存空间,这样一共就只需要4个变量的存储空间。
另外,MegEngine 还使用了算子融合 (Operator Fuse)的机制,用于减少计算开销。对于上面的动态计算图,切换为静态图后可以将乘法和加法融合为一个三元操作(假设硬件支持):乘加(如下图所示),从而降低计算量。




