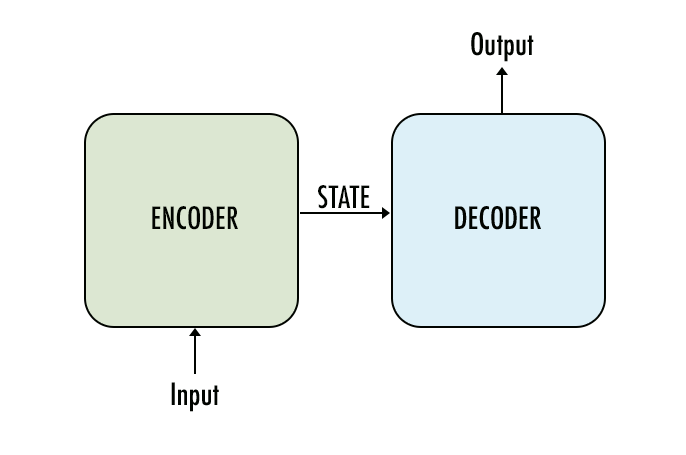
If we take a high-level view, a seq2seq model has encoder, decoder and intermediate step as its main components:
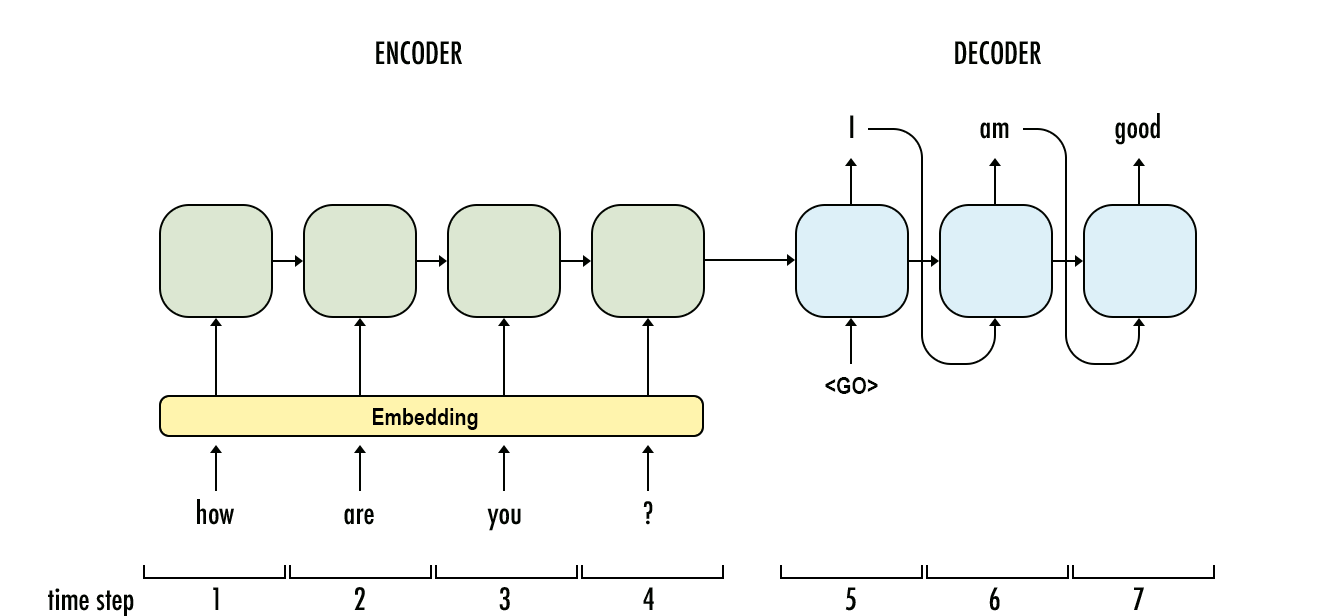
We use embedding, so we have to first compile a “vocabulary” list containing all the words we want our model to be able to use or read. The model inputs will have to be tensors containing the IDs of the words in the sequence.
There are four symbols, however, that we need our vocabulary to contain. Seq2seq vocabularies usually reserve the first four spots for these elements:
: During training, we’ll need to feed our examples to the network in batches. The inputs in these batches all need to be the same width for the network to do its calculation. Our examples, however, are not of the same length. That’s why we’ll need to pad shorter inputs to bring them to the same width of the batch : This is another necessity of batching as well, but more on the decoder side. It allows us to tell the decoder where a sentence ends, and it allows the decoder to indicate the same thing in its outputs as well. : If you’re training your model on real data, you’ll find you can vastly improve the resource efficiency of your model by ignoring words that don’t show up often enough in your vocabulary to warrant consideration. We replace those with . : This is the input to the first time step of the decoder to let the decoder know when to start generating output.
Note: Other tags can be used to represent these functions. For example I’ve seen < s > and < /s > used in place of
In this article, I will try to give a short and concise explanation of the sequence to sequence model which have recently achieved significant results on pretty complex tasks like machine translation, video captioning, question answering etc.
Prerequisites: the reader should already be familiar with neural networks and, in particular, recurrent neural networks (RNNs). In addition, knowledge of LSTM or GRU models is preferable. If you are not yet familiar with RNNs, I recommend reading this article which will give you a quick start. For LSTM and GRU, I suggest looking into “Understanding LSTM Networks” as well as “Understanding GRU Networks”.
Why?——Use Cases of the Sequence to Sequence Model
A sequence to sequence model lies behind numerous systems which you face on a daily basis. For instance, seq2seq model powers applications like Google Translate, voice-enabled devices and online chatbots. Generally speaking, these applications are composed of:
Machine translation — a 2016 paper from Google shows how the seq2seq model’s translation quality “approaches or surpasses all currently published results”.
Speech recognition — another Google paper compares the existing seq2seq models on the speech recognition task.

Video captioning — a 2015 paper shows how a seq2seq yields great results on generating movie descriptions.

These are only some applications where seq2seq is seen as the best solution. This model can be used as a solution to any sequence-based problem, especially ones where the inputs and outputs have different sizes and categories. We will talk more about the model structure below.
What?——Definition of the Sequence to Sequence Model

Introduced for the first time in 2014 by Google, a sequence to sequence model aims to map a fixed-length input with a fixed-length output where the length of the input and output may differ.
For example, translating “What are you doing today?” from English to Chinese has input of 5 words and output of 7 symbols (今天你在做什麼?). Clearly, we can’t use a regular LSTM network to map each word from the English sentence to the Chinese sentence.
不能直接使用LSTM的原因在于:
“What are you doing today?”与“今天你在做什麼?”不是Aligned的,如果使用LSTM那样一个timestamp对应一个output是不符合逻辑的。
This is why the sequence to sequence model is used to address problems like that one.
How——How the Sequence to Sequence Model works?
In order to fully understand the model’s underlying logic, we will go over the below illustration:
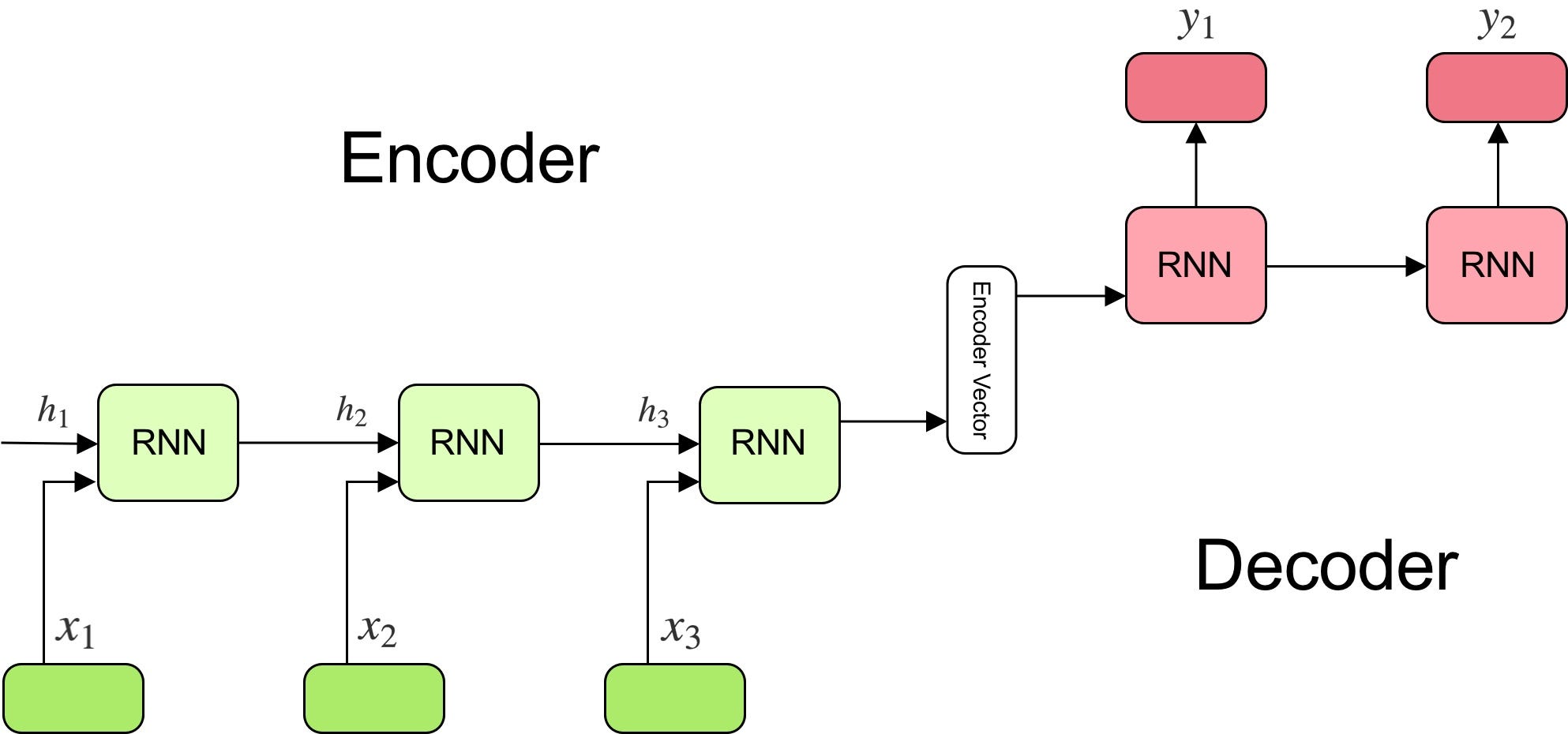
The model consists of 3 parts:
- encoder;
- intermediate (encoder) vector;
- decoder;
Encoder
A stack of several recurrent units (
LSTMorGRUcells for better performance) where each accepts a single element of the input sequence, collects information for that element and propagates it forward.In question-answering problem, the input sequence is a collection of all words from the question. Each word is represented as x_i where i is the order of that word.
The hidden states h_i are computed using the formula:
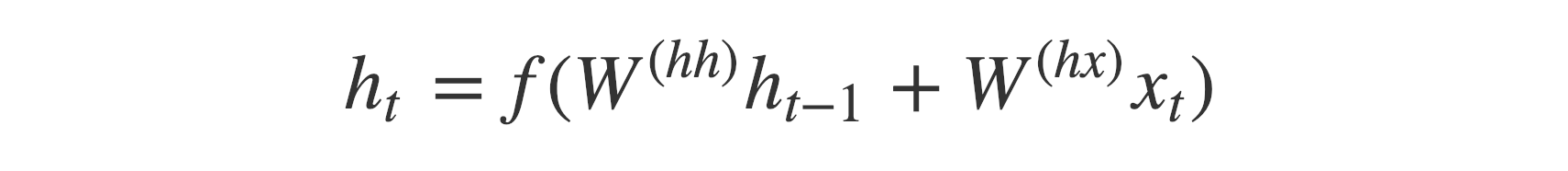
This simple formula represents the result of an ordinary recurrent neural network. As you can see, we just apply the appropriate weights to the previous hidden state h_(t-1) and the input vector x_t.
Encoder Vector
- This is the final hidden state produced from the encoder part of the model. It is calculated using the formula above.
- This vector aims to encapsulate the information for all input elements in order to help the decoder make accurate predictions.
- It acts as the initial hidden state of the decoder part of the model.
Decoder
A stack of several recurrent units where each predicts an output y_t at a time step t.
Each recurrent unit accepts a hidden state from the previous unit and produces output as well as its own hidden state.
In the question-answering problem, the output sequence is a collection of all words from the answer. Each word is represented as y_i where i is the order of that word.
Any hidden state h_i is computed using the formula:
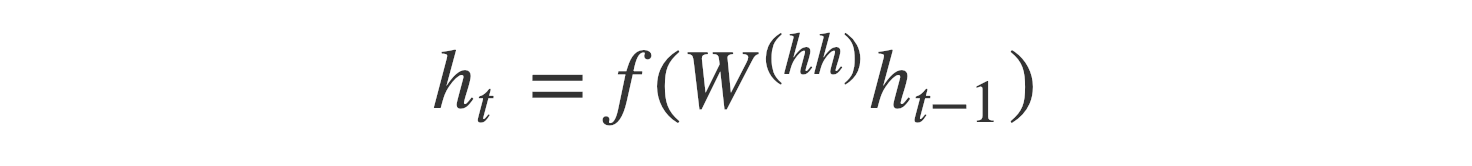
As you can see, we are just using the previous hidden state to compute the next one.
The output y_t at time step t is computed using the formula:
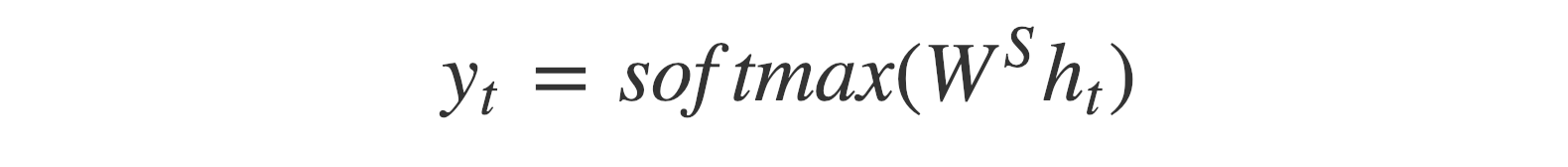
We calculate the outputs using the hidden state at the current time step together with the respective weight W(S). Softmax is used to create a probability vector which will help us determine the final output (e.g. word in the question-answering problem).
The power of this model lies in the fact that it can map sequences of different lengths to each other. As you can see the inputs and outputs are not correlated and their lengths can differ. This opens a whole new range of problems which can now be solved using such architecture.
Further Reading
The above explanation just covers the simplest sequence to sequence model and, thus, we cannot expect it to perform well on complex tasks. The reason is that using a single vector for encoding the whole input sequence is not capable of capturing the whole information.
This is why multiple enhancements are being introduced. Each one aims to strengthen the performance of this model on slightly complex tasks with long input and output sequences. Examples are:
- Reversing the order of the input sequence.
- Using LSTM or GRU cells.
- Introducing Attention mechanism.
- and many more.
If you want to strengthen your knowledge of this wonderful deep learning model, I strongly recommend watching Richard Socher’s lecture on Machine Translation.



