NLP的两大任务
前言:之前我们讲了很多与语音处理有关的任务,这次我们来讲和自然语言处理相关的任务。NLP任务大体可以分成两大类:
- 文本序列到文本序列,比如机器翻译,文本风格迁移等;
- 序列到类别,比如情感分类,实体命名识别,主题分类,槽位填充(Slot Filling)等。
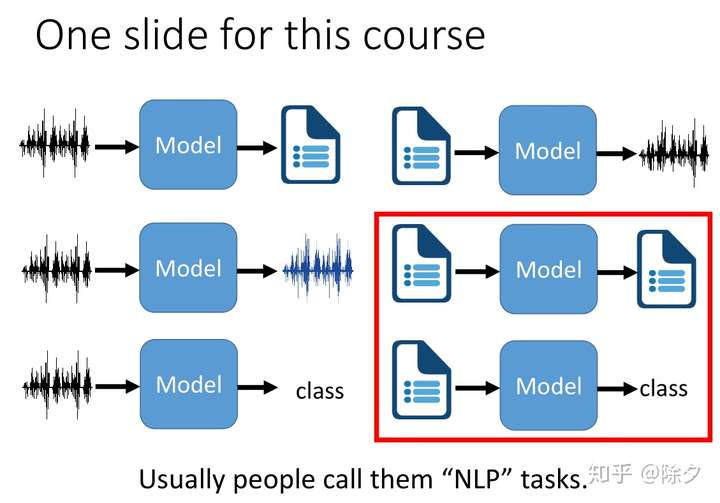
NLP 这个词的用法有点模糊。Language 指的一般是人与人沟通时用的语言。因此 Natural Language 可以是文字也可以是语音。因此语音相关的技术,也应该算是 Natural Language 的范畴。但不知道为什么,一般我们在将自然语言处理的时候,指的都是文字处理相关的技术。而语音生成,语音分类和语音的风格转换,却被分成语音处理了。自然语言处理的应用非常广泛。尽管其变化多端,但无非是以下几种任务的变体。
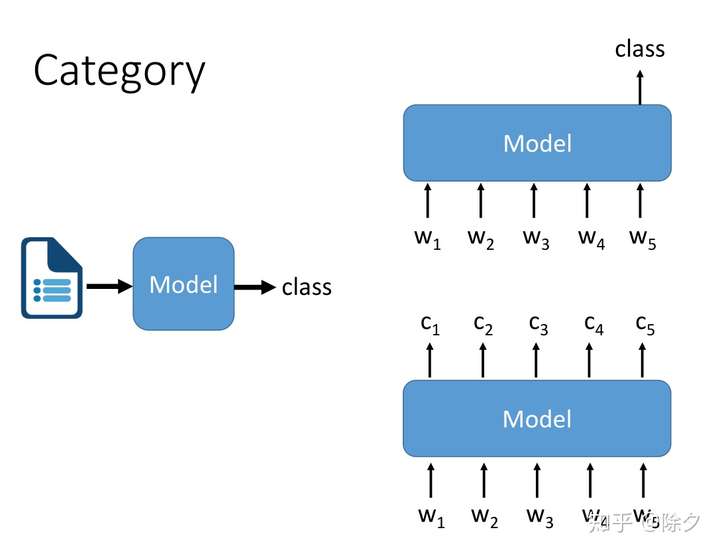
文本到类别可以分成两种:
- 一种是输入序列输出代表这整个序列的类别,如情感分类。
- 另一种是输入序列输出序列上每个位置的类别,如实体命名识别。
它们都可以接一个 LSTM Model来获取序列的上下文标注,后面再接一个 MLP 做线性映射,再用 sigmoid 或 softmax 来输出类别。
目前流行的方式都是使用BERT来作为Model,而不是LSTM。
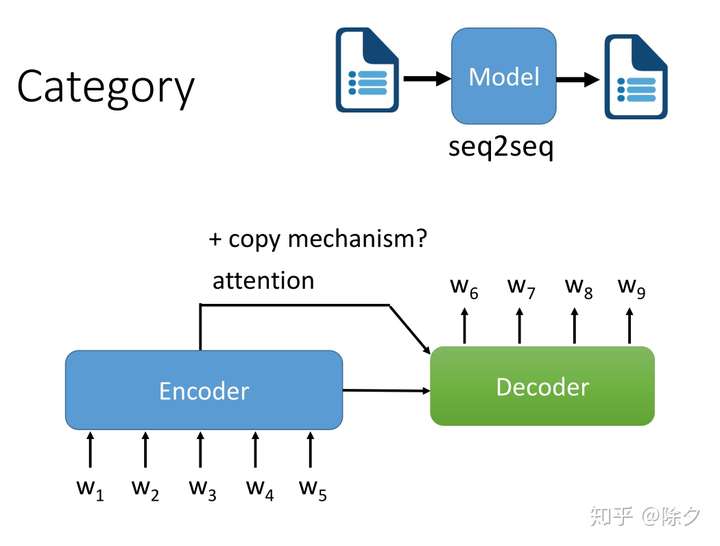
文本到文本则倾向于使用 Seq2Seq Model,Encoder-Decoder 架构,中间需要用 attention 来对齐。
对于有些输入文字和输出文字内容有很多重复的任务,比如文本摘要,拼写检查,语法纠错,标题改写这类任务,我们还需要在中间加入复制的能力。比如 pointNet 和 CopyNet。
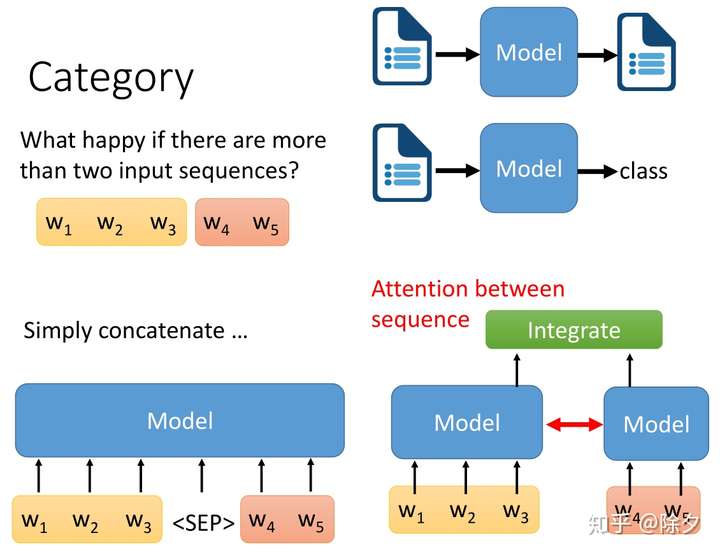
如果输入的是多个序列要怎么办呢?我们有大概两种可能的解法:
- 一种是把两个序列,分别用两个模型去做编码。再把它们编码后的嵌入,丢给另一个整合的模块,去得到最终的输出。有时,我们也会在两个模型之间加 Attention,确保二者的编码内容能互相意识。
- 近年来比较流行的做法是直接把两个句子连接起来,中间加一个特殊的字符,如 BERT 里面的
,来提示模型去意识到这是两个句子的分隔符。接起来的序列丢给模型后,就可以直接预测下游任务。
一表览尽NLP的所有子任务⭐⭐⭐⭐⭐
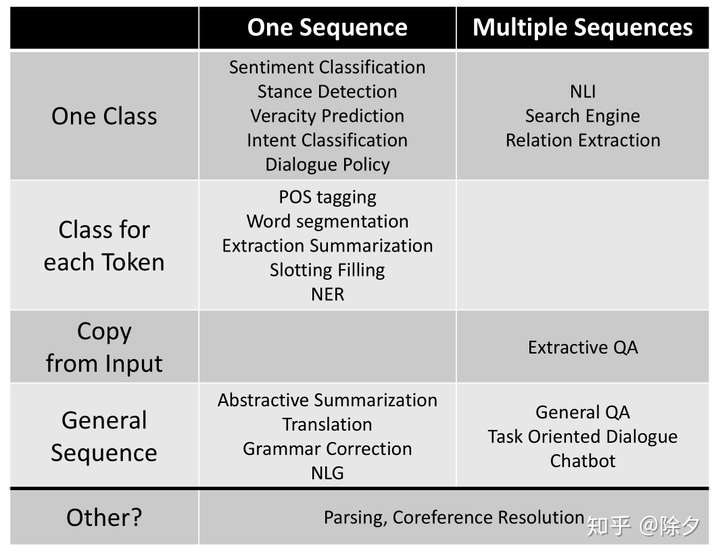
虽然 NLP 的任务千变万化,但根据模型的输入输出可以分成几个大类。模型的输入可以分成一个序列和多个序列,模型的输出可以分成整个序列一个类别,每个位置都有类别,是否需要复制输入,还是要输出另一端文本。除了这些以外,还有一些例外,比如 Parsing 和 Coreference Resolution。
Part-of-Speech(POS) Tagging
part n. 部分;角色;零件;一些;片段
speech n.语言,说话
part-of-speech:说话中词的角色=> 词的类别,简称词性。
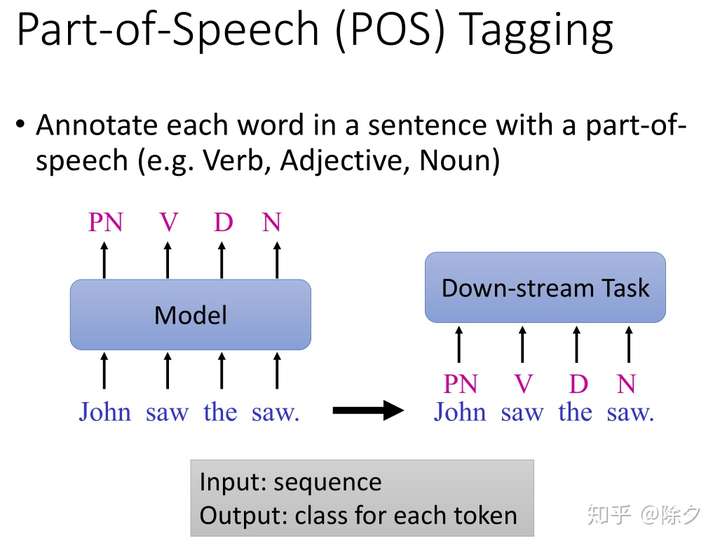
Part-of-Speech (POS) Tagging 词性标注 需要我们标记出一个句子中的每个词的词性是什么。对应输入一个序列,输出序列每个位置的类别任务。
output的标记类别可以用作下游任务(比如文本摘要,机器翻译)的input。
Word Segmentation
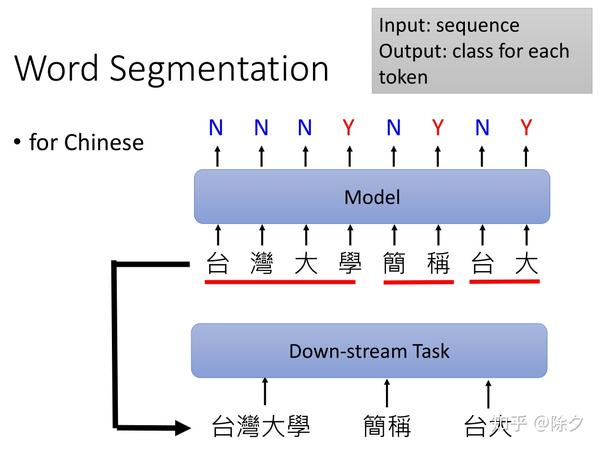
中文分词。英文词汇有空格符分割词的边界,但中文中,却没有类似的方式来区分,所以我们需要中文分词。在一个句子中找出词的边界有时并不是一个简单的问题,所以也需要模型来做。一般中文分词是对句子中的每个字的位置做二分类。如果标注为Y,表示这个字是词汇的结尾边界,如果标注为 N,表示这个字不是词汇的结尾。到了下游任务,我们就可以利用分好的词来作为模型输入的基本单位,而不一定用字。但是否有必要用词表征来替代字表征还是一个值得探究的问题。因为 BERT 在处理中文的时候,它已经不是以字为基本单位了。它很有可能已经自动学到了分词这件事。因此输入要不要用词表征倒显得无关紧要。但 BERT-wwm(它相比于Bert的改进是用Mask标签替换一个完整的词而不是子词)的实验表明,预训练过程中,让 BERT 要预测的随机 MASK 掉的是一个分词的 span 而不是单独的字能表现更好。说明知道词汇的边界在哪里,对语义的理解是非常重要的。
Parsing
- Parsing这个词,可以翻译为句法分析,也可以翻译为语法分析。
- Parsing这个任务的输入和输出不符合我们之前表格的分类,以后会当做一个特殊的专题讨论。
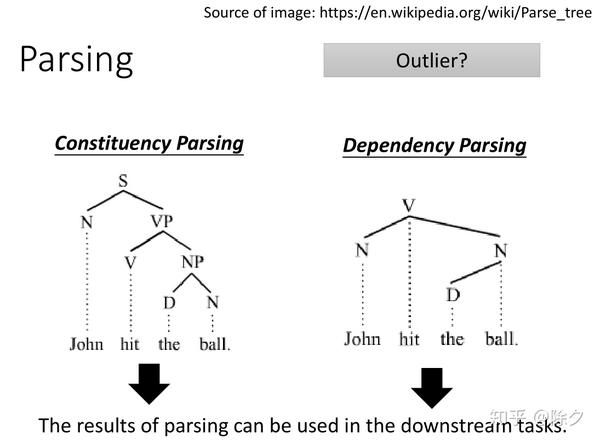
还有一些也会用来作为自然语言理解的前处理的任务,比如说 Parsing。它的输入是一个句子,输出是一棵句法树。它的输出有时会被当作是额外的特征,在接下来的任务中被使用到。

另一个也常来做前处理的任务叫指代消解 Coreference Resolution。模型需要把输入文章中指代同样东西的部分,找出来。比如文中,He 和 Paul Allen 指的就是同一个人。
Summarization
Extractive Summarization & Abstractive Summarization
Extractive Summarization
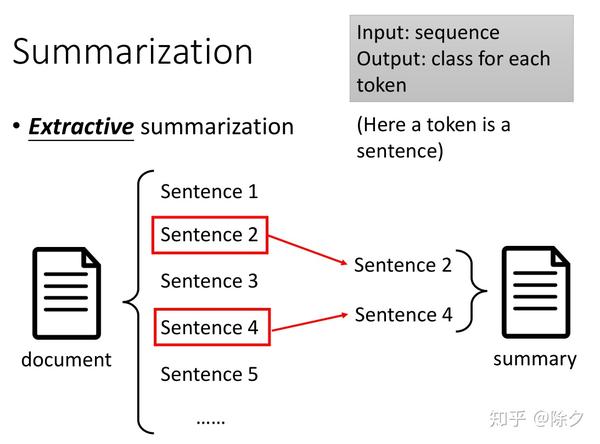
接下来是摘要,它可以分成两种。过去常用的是抽取式摘要。把一篇文档看作是许多句子的组成的序列,模型需要从中找出最能熔炼文章大意的句子提取出来作为输出。它相当于是对每个句子做一个二分类,来决定它要不要放入摘要中。但仅仅把每个句子分开来考虑是不够的。我们需要模型输入整篇文章后,再决定哪个句子更重要。这个序列的基本单位(Token)是一个句子的表征。
Abstractive Summarization

随着深度学习的近年流行,人们开始关注生成式摘要了。模型的输入是一段长文本,输出是短文本。输出的短文本往往会与输出的长文本有很多共用的词汇。这就需要模型在生成的过程中有把文章中重要词汇拷贝出来,放到输出中的复制的能力,比如 Pointer Network。

输入文字或语音可以直接输出文字。为什么我们要做输入语音输出翻译文字的翻译模型呢?因为很多语言比如说当地的一些方言,连文字都没有。我们只能做语音到文字的对应。如果我们输入输出的语言都没有文字,我们有机会做语音到语音的翻译。对于机器翻译领域来说,一个很关键的问题就是无监督学习。因为世界上的语言有非常多,大约7000种语言。两两匹配大约有 7000² 对组合。我们现实中很难收集到所有的两两语言组合,这是不切实际的。因此无监督学习是很有必要的。模型通过看了一大段英文句子,也看了一大段中文句子,但没有给出中文和英文的对应关系,却能够自动学会把英文转换为中文,把中文转换为英文。(后面的课程会讲解如何实现这样的无监督机器翻译)
Grammar Error Correction

语法改错任务,也是文本序列到文本序列,理所当然会想到使用Seq2Seq Model。考虑到输入和输出有很多字是重复的,我们考虑用一些复制机制,让模型把没有错的词汇保留下来。
这种语法改错任务其实还可以更进一步简化,不使用Seq2Seq Model。输入是一个序列,输出是该序列上每个位置的类别标注。如上图中右半部分所示,标注类型包括是要保留复制,还是置换,还是插入。
C stands for 保留
R stands for 置换
A stands for 插入
Sentiment Classification

序列到类别则包括商品评论情感分类。句子中可以同时包括正面的词汇和负面的词汇,模型需要根据上下文学到语境中更侧重正面还是负面。比如虽然……但是这种转折关系,”但是”后面的词汇会得到更多的侧重。
Stance Detection
stance detection,中文翻译为立场检测。

立场检测任务也是分类。它的输入是两个序列,输出是一个类别,表示后面的序列是否与前面的序列站在同一立场。常用的立场检测包括 SDQC 四种标签,**支持 (Support),否定 (Denying),怀疑 (Querying),Commenting (注释)**。
Veracity Prediction
- veracity /vəˈræsəti/ n. 真实,准确
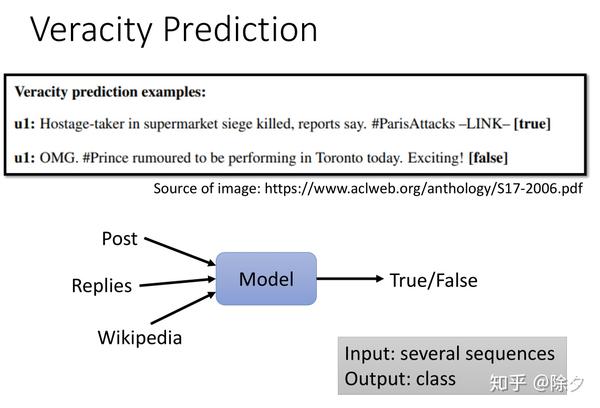
事实验证也是文本分类的一种。模型需要看一篇新闻文章,判断该文章内容是真的还是假的。假新闻检测是典型的。有时从文章本身,我们人自己都很难判断它的真假。因此有时我们还需要把文章的回复评论也加入模型的输入,去预测真假。如果一个文章它回应第一时间都是否认,往往这个新闻都是假新闻。我们还可以让模型看与文章有关的维基百科的内容,来增强它的事实审核能力。
Natural Language Inference(NLI)

- premise:前提
- hypothesis:假设
还有一类任务叫自然语言推断 (NLI)。输入给模型的是一个陈述前提,和一个假设,输出是能否通过前提推出假设,它包含三个类别,分别是矛盾,蕴含和中性。比如前提是,一个人骑在马上跳过一架破旧的飞机,假设是这个人正在吃午餐。这显然是矛盾的。因为前提推不出假设。如果假设是,这个人在户外,在一匹马上。则可以推理出蕴含。再如果假设是这个人正在一个比赛中训练他的马。则推理不能确定,所以是中性的。
Search Engine
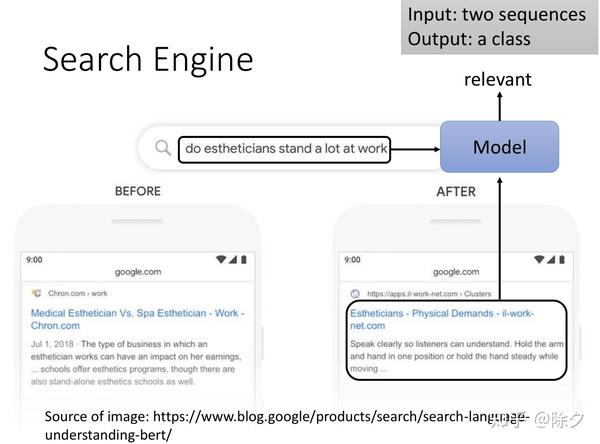
再往下的任务是搜索引擎。模型的输入是一个关键词或一个问句和一堆文章,输出是每篇文章与该问句的相关性。谷歌有把 BERT 用在搜素引擎上在语义理解上得到了提升。比如搜帮你做美容的人是否经常站着工作。没有 BERT 之前,模型会利用关键词 estheticians 和 stand-alone 做合并结果输出。但有了 BERT 之后,搜出的结果会更倾向于文章语义的理解而非单纯的关键字匹配。
总结:李宏毅这节课汇总了大部分的典型 NLP 任务,下节课会讲问答系统,对话系统,信息抽取和文本生成等任务。当然还有一些其它任务,比如常识推理,文本主题模型聚类,时间处理等任务没有讲到。但不得不说,深入浅出,覆盖很全面。一遍看下来,对初学者而言可以构建知识体系,对进阶者而言可以查缺补漏。最后赠送一张 NLP 双生树思维导图作为福利。这两个月增粉很多,感谢大家一直以来的关注。
Question Answering
前言:接上一期继续讲剩下的问答系统,对话系统,信息抽取和文本生成等 NLP 任务。
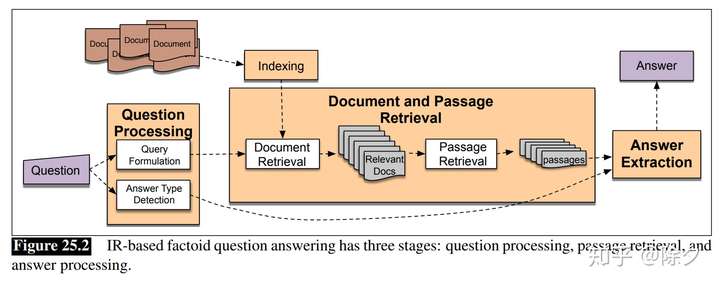
问答系统一般都是基于检索式的,会有如下几个模块:
- Question Processing:问题预处理(Query 规范化表示,答案类型)
- Document and Passage Retrieval:用 Query 去召回一波文档,根据一系列的特征去做排序,找出相关性较强的段落
- Answer Extraction:对候选答案评分再排序、用答案类型去约束提取出的候选答案,返回最终结果
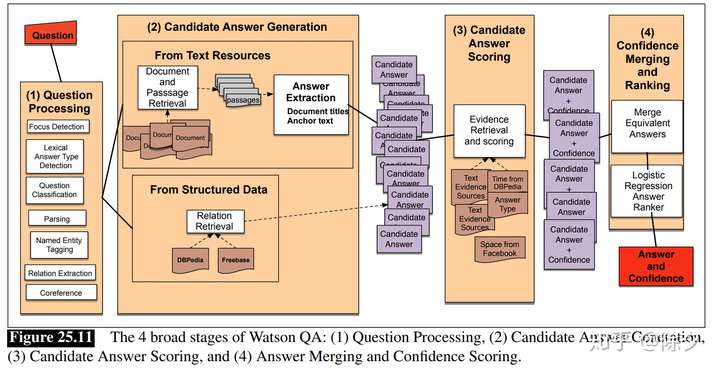
Watson 之所以强大是因为它把每个模块部分做的非常的精细。光问题处理的答案类型它就有几千个,使用了很多特征。在候选答案生成中,它也利用了海量的文档资源。输出的候选答案之后,它还会根据证据做进一步的再排序,选出置信度最高的那个答案。

Extractive QA
QA问题的输入是一连串句子,输出是答案序列。搜索引擎只是做相关性检索,但如果想要理解文档篇章,还是需要机器阅读理解。
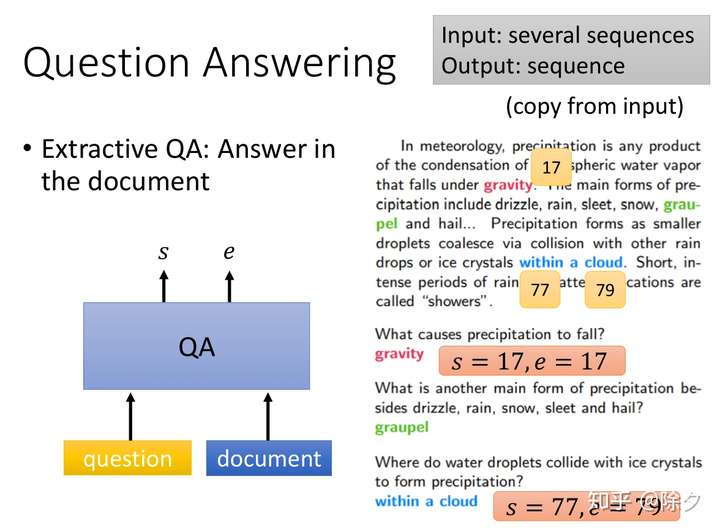
当前主流的研究,其实并没有让模型吐出完整的答案。通常我们做的是抽取式的QA,即给定一段文章和问题,模型需要输出答案在文章段落中的位置。它是强制复制原文中的内容,而不是自主生成能基于文章回答问题,但不在文章中的答案。
Chatting
对话机器人可以分成两种,闲聊(Chatting)和任务导向型(Task-oriented)。闲聊机器人基本上都是在尬聊,有一堆问题待解决,比如角色一致性,多轮会话,对上下文保有记忆等。
Chatbot
当前的闲聊机器人需要有一致的人格,懂常识和领域知识,有同理心。
Task-Oriented
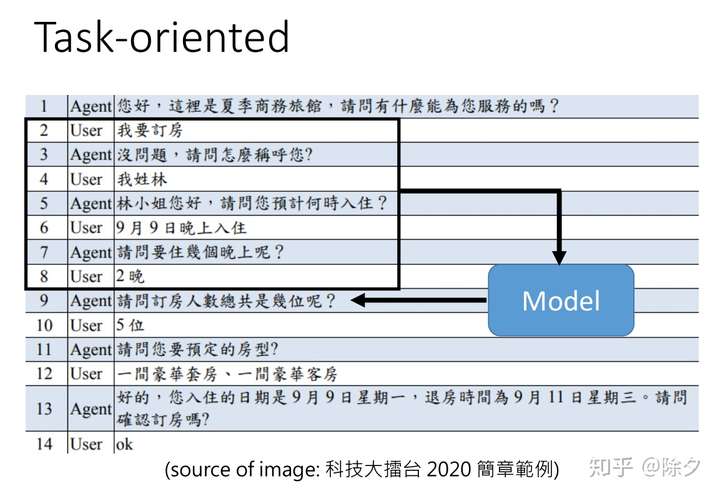
任务导向的对话机器人能够协助人完成某件事,比如订机票,调闹钟,问天气等。我们需要一个模型把过去已经有的历史对话,统统都输入到一个模型中,这个模型可以输出一个序列当作现在机器的回复。(结合上下文来聊天~)一般而言,我们会把这个模型再细分成很多模块,而不会是端对端的。
Natural Language Generation(NLG)
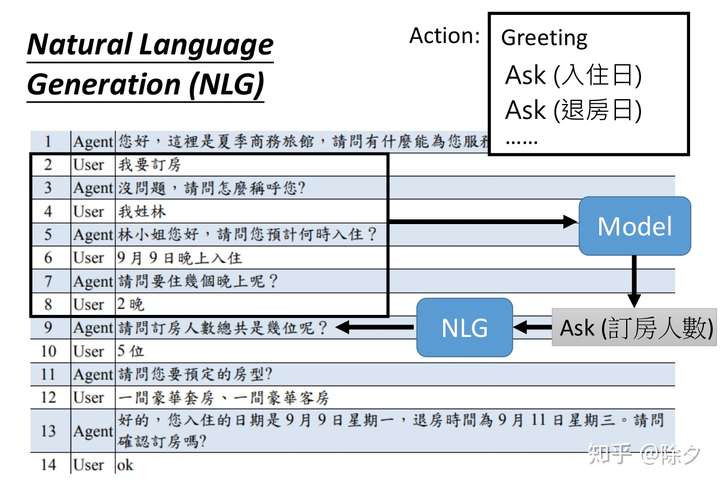
这些模块通常包括自然语言理解NLU,行动策略管理,以及自然语言生成NLG。自然语言理解负责根据上下文去理解当前用户的意图,方便选出下一步候选的行为,如执行系统操作,澄清还是补全信息,确定好行动之后,自然语言生成模块会生成出对齐行动的回复。
Policy & State Tracker
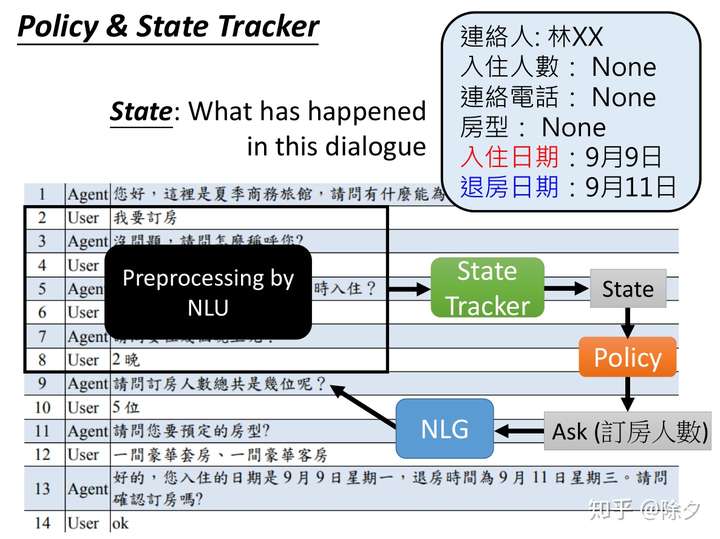
具体地说,NLU 会用来根据上下文来理解哪些信息是对当前任务重要的,比如订房任务中的联系人,入住人数,入住日期等。理解出的信息,会变成一个类别作为状态,交给策略管理模块去判断当前还有哪些信息缺失,是否需要继续询问,还是说信息已经全部补全,可以执行命令。如果是要补充信息,则要根据缺失的信息去让自然语言生成模块生成问题。
Natural Language Understanding(NLU)
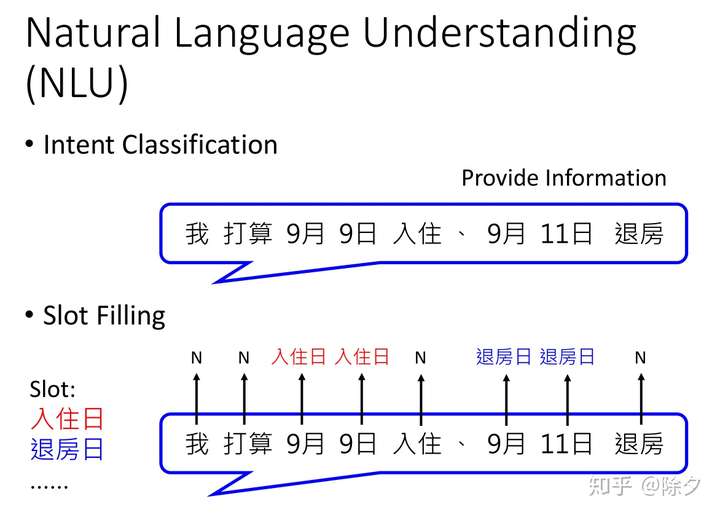
NLU 模块在任务型对话机器人中,通常会有两个任务:
- 意图识别(Intent Classification)
- 槽位填充(Slot Filling)
Intent Classification & Slot Filling
意图识别需要弄清楚用户在做什么,是提供信息还是询问问题,它是一个分类任务。假如确认了用户是在提供信息,则槽位填充任务需要从用户回复文本中提取出关键信息,如时间,地点,对应的是入住时间还是退房时间等。但如果意图识别出的是询问问题,比如9月9号还有没有空房,那9月9号就可能不是入住的日期。而是要根据当天有无空房间来进行判断。
槽位填充实质在做的与实体命名识别一样。
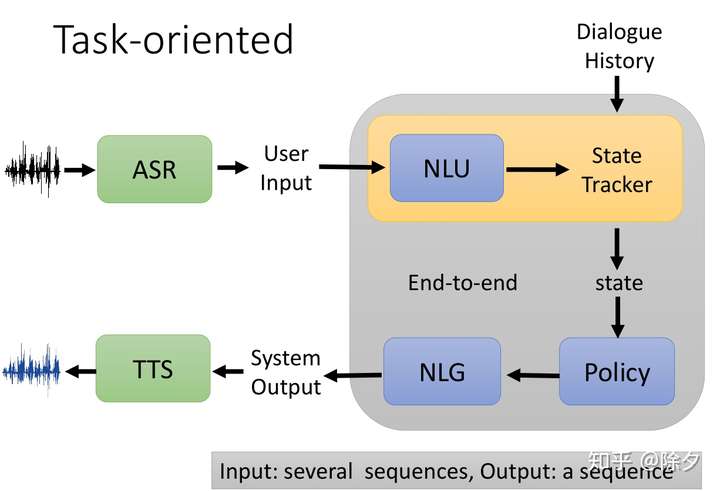
除了之前三个模块,语音助理中,再加上语音识别 ASR 和 语音合成 TTS 就成了完整的对话系统。
Knowledge Extraction
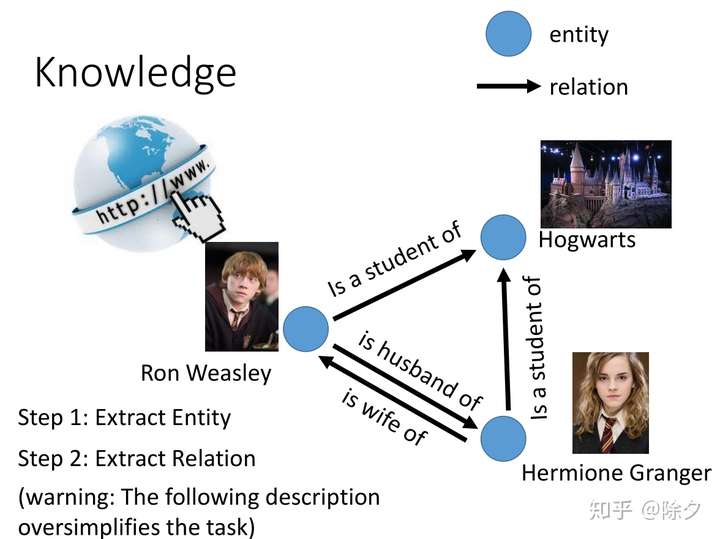
知识图谱的构建简化地去理解可以看作是实体提取和关系抽取。实体可以是人可以是物,也可以是组织机构,非常灵活。关系可以是人与人的关系,可以是谓语动作,也可以是企业之间的资本流动。信息抽取任务希望从海量文本中自动挖掘出实体关系三元组。这个问题其实非常地复杂。这里只是简单地讲。
Name Entity Recognition(NER)

什么是实体命名识别呢?其实命名实体它的内容并没有非常清楚的定义。它取决于我们对哪些事情关心。随着领域的不同,有所差异。一般的实体包括人名、组织和地名等等。但这不是完整的实体的定义。它取决于我们的具体应用。比如我们想让机器读大量医学相关的文献,希望它自动知道有什么药物可以治疗新冠状肺炎。这些药物的名字,就是实体。它输入的是一个序列,输出的是序列上每个位置的类别。它就和词性标注、槽位填充一样。
NER常见的两个问题是:
- 名字一样但指的是不同的东西,有多个标签需要实体消歧;
- 不一样的名字指的却是相同的东西,需要实体归一化。
总之,怎么抽取实体是有非常多的相关研究。
Relation Extraction
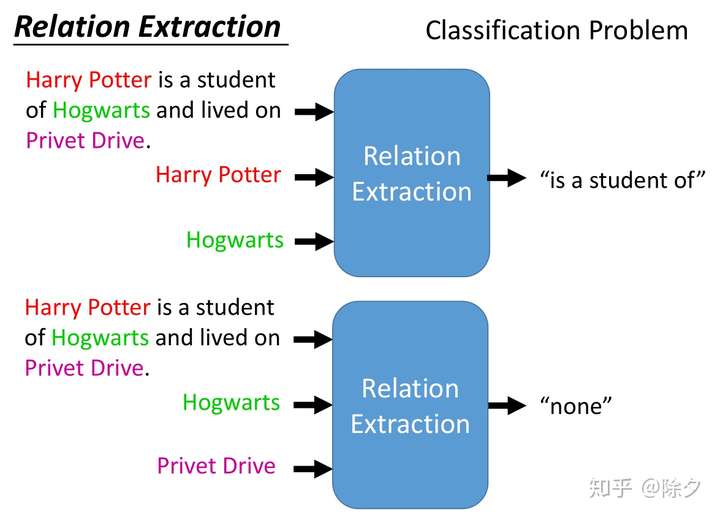
假如我们知道如何从文本中获得实体,接下来还需要知道它们之间的关系。比如哈利波特是霍格沃茨的学生。关系抽取的输入是序列和抽取出的实体,输出是两两实体之间的关系。它是一个分类任务。
GLUE

过去往往是一个NLP任务设计一个模型。听起来不是非常地智能。我们希望知道模型在各种任务上的一般表现。于是就有了一些标准和竞赛,Benchmark。一个知名的竞赛叫作 GLUE,主办方集合了很多觉得重要的能理解人类语言有关的任务,希望我们的模型能去解这些任务,看看可以得到什么样的结果。GLUE中任务分成三大类:
- 第一大类是分类任务,包括语法错误检测和情感分类。它们都是输入是一个序列,输出是一个类别;
- 第二大类是输入是两个句子,输出是二者的语义是否相似对应;
- 第三大类都是自然语言推理相关的任务。输入前提和假设,希望机器能判断二者是否矛盾蕴含还是无关。GLUE 并没有涵盖所有的 NLP 类型问题。


有了 BERT 和它的好朋友以后,GLUE指标都被打破稍微有些超出人类的表现了,所以需要新的 Benchmark,于是就有了 Super GLUE。它的任务大都是和 QA 比较有关系的,比如:
- 输入一个段落,询问一个一般疑问句,回答是yes or no。(BoolQ,COPA,MultiRC)
- 或者是常识、逻辑推理。(CB,RTE)
- 也有是把看一个段落,回答填空的。(ReCoRD)
- 或者是给机器两个句子,两个句子中都有同样的词汇。看看机器能不能知道这两个词汇意思是一样的还是不是一样的。(WiC)
- 或者是给机器一个句子,句子上标了一个名词和一个代名词,希望机器能够判断二者是不是指代同一个东西。(WSC)
DecaNLP
十项全能NLP
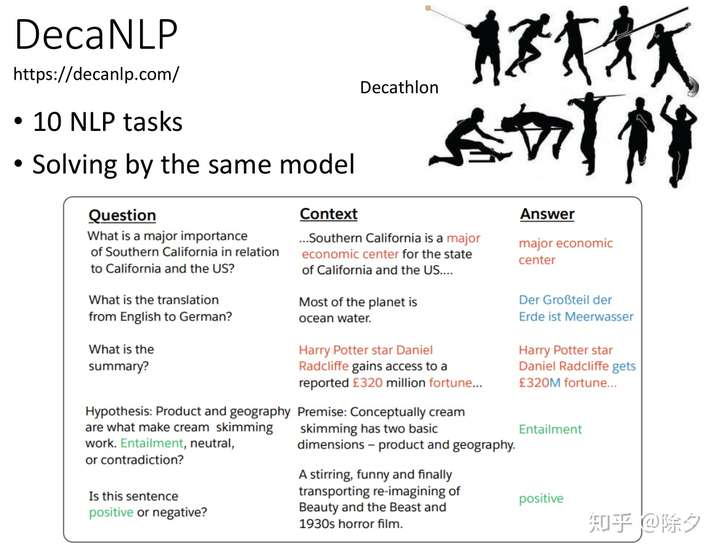
除了Super GLUE 以外,还有一个 Benchmark 叫 DecaNLP。它希望你用同一个模型来解决十个不同的任务。Super GLUE 虽然比 GLUE 增加了难度,但它大多数也还是分类任务,近年来也一直被刷榜。而DecaNLP中它的任务会更加困难,很多任务像摘要、翻译需要输出一个完整的句子。所有这些不同的任务,都可以看作是 QA 类型问题。怎么把各式各样的 NLP 任务看成是 QA 问题呢?比如翻译就是给定一段要把A语言翻译成B语言的问句,和一段文章,希望机器能把这段文章翻译成指定语言。摘要情感分类也是类似的。谷歌的 T5 Text-to-Text 模型,就可以做类似的。把不同任务用统一框架集成起来的好处有两个:
- 一是可以评估一个模型的综合表现;
- 二是可以促进研究者寻找出更通用的自然语言处理模型。
后记:真心推荐访问一下 DecaNLP 的链接去看一下它的 Benchmark。QA 框架统一各种任务非常值得模型来刷榜。这其实也是多任务学习的一个研究方向。
学习Model的方法
When
哪一年发布的Model?
Why
Model产生的背景?
What
Model的图示是怎样的?
Who
哪个团队提出来的?
Where
在哪篇paper上提出来的?
How
Model的实现细节
Practice
代码实战,主要使用PyTorch~



