原文章地址——预训练模型超全知识点梳理与面试必备高频FAQ
预训练模型(Pre-trained Models,PTMs)的出现将NLP带入了一个全新时代。2020年3月18日,邱锡鹏老师发表了关于NLP预训练模型的综述《Pre-trained Models for Natural Language Processing: A Survey》,这是一篇全面的综述,系统地对PTMs进行了归纳分类。
本文以此篇综述论文为主要参考,通过借鉴不同的归纳方法进行总结,同时也整合了专栏之前已经介绍过的《nlp中的词向量对比》和《nlp中的预训练语言模型总结》两篇文章,以QA形式对PTMs进行全面总结归纳。
获取总结图片下载以及单模型精读请到 github:NLP预训练模型的全面总结,希望为大家的学习工作提供一些帮助。
笔者注:本文总结与原综述论文也有一些不同之处(详见文末),如有错误或不当之处请指正。很多总结归纳的点不太好拿捏,大家多给意见~
一、为什么要进行预训练?(Why?)
深度学习时代,为了充分训练深层模型参数并防止过拟合,通常需要更多标注数据喂养。在NLP领域,标注数据更是一个昂贵资源。PTMs从大量无标注数据中进行预训练使许多NLP任务获得显著的性能提升。总的来看,预训练模型PTMs的优势包括:
- 在庞大的无标注数据上进行预训练可以获取更通用的语言表示,并有利于下游任务;
- 为模型提供了一个更好的初始化参数,在目标任务上具备更好的泛化性能、并加速收敛;
- 是一种有效的正则化手段,避免在小数据集上过拟合(一个随机初始化的深层模型容易对小数据集过拟合);
二、什么是词嵌入和分布式表示?PTMs与分布式表示的关系?What
词嵌入是自然语言处理(NLP)中语言模型与表征学习技术的统称。概念上而言,它是指把一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量,这也是分布式表示:向量的每一维度都没有实际意义,而整体代表一个具体概念。
分布式表示相较于传统的独热编码(one-hot)表示具备更强的表示能力,而独热编码存在维度灾难和语义鸿沟(不能进行相似度计算)等问题。传统的分布式表示方法,如矩阵分解(SVD/LSA)、LDA等均是根据全局语料进行训练,是机器学习时代的产物。
PTMs也属于分布式表示的范畴,本文的PTMs主要介绍深度学习时代、自NNLM以来的 “modern” 词嵌入。
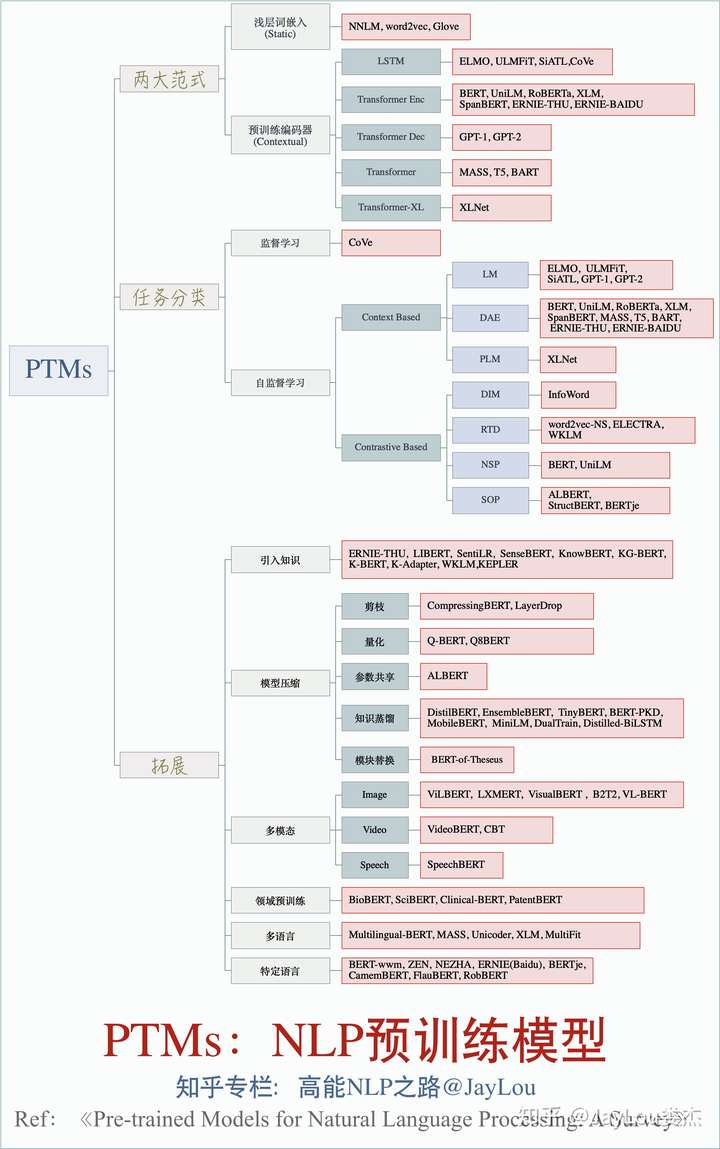
三、PTMs有哪两大范式?对比不同的预训练编码器?How
PTMs的发展经历从浅层的词嵌入到深层编码两个阶段,按照这两个主要的发展阶段,我们归纳出PTMs两大范式:「浅层词嵌入」和「预训练编码器」。
1、浅层词嵌入( Non-Contextual Embeddings)
浅层词嵌入,这一类PTMs范式是我们通常所说的“词向量”,其主要特点是学习到的是上下文独立的静态词嵌入,其主要代表为NNLM、word2vec(CBOW、Skip-Gram)、Glove等。这一类词嵌入通常采取浅层网络进行训练,而应用于下游任务时,整个模型的其余部分仍需要从头开始学习。因此,对于这一范式的PTMs没有必要采取深层神经网络进行训练,采取浅层网络加速训练也可以产生好的词嵌入。
浅层词嵌入的主要缺陷为:
- 词嵌入与上下文无关,每个单词的嵌入向量始终是相同,因此不能解决一词多义的问题。
- 通常会出现OOV问题,为了解决这个问题,相关文献提出了字符级表示或sub-word表示,如CharCNN 、FastText 和 Byte-Pair Encoding。

图1给出了三种常见的浅层词嵌入之间的对比,Glove可以被看作是更换了目标函数和权重函数的全局word2vec。此外,相关文献也提出了句子和文档级别的嵌入方式,如 Skip-thought 、Context2Vec 等。
2、预训练编码器(Contextual Embeddings)
第二类PTMs范式为预训练编码器,主要目的是通过一个预训练的编码器能够输出上下文相关的词向量,解决一词多义的问题。这一类预训练编码器输出的向量称之为「上下文相关的词嵌入」。

图2给出了NLP各种编码器间的对比。PTMs中预训练编码器通常采用LSTM和Transformer(Transformer-XL),其中Transformer又依据其attention-mask方式分为Transformer-Encoder和Transformer-Decoder两部分。此外,Transformer也可看作是一种图神经网络GNN。
这一类「预训练编码器」范式的PTMs主要代表有ELMO、GPT-1、BERT、XLNet等。
四、PTMs按照任务类型如何分类?
PTMs按照任务类型可分为2大类:监督学习 和 无监督学习/自监督学习。
监督学习在NLP-PTMs中的主要代表就是CoVe,CoVe作为机器翻译的encoder部分可以应用于多种NLP下游任务。除了CoVe外,NLP中的绝大多数PTMs属于自监督学习。
自监督学习是无监督学习的一种方法,自监督学习主要是利用辅助任务从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。因此,从“构造监督信息”这个角度来看,自监督也可看作是监督学习和无监督学习的一种融合。严格地讲,从是否由人工标注来看,自监督学习属于无监督学习的范畴。
综合各种自监督学习的分类方式,笔者将NLP-PTMs在自监督学习中分为两种类型:基于上下文(Context Based)和基于对比(Contrastive Based)。
1、基于上下文(Context Based)



