Transformer
画Transformer的结构图
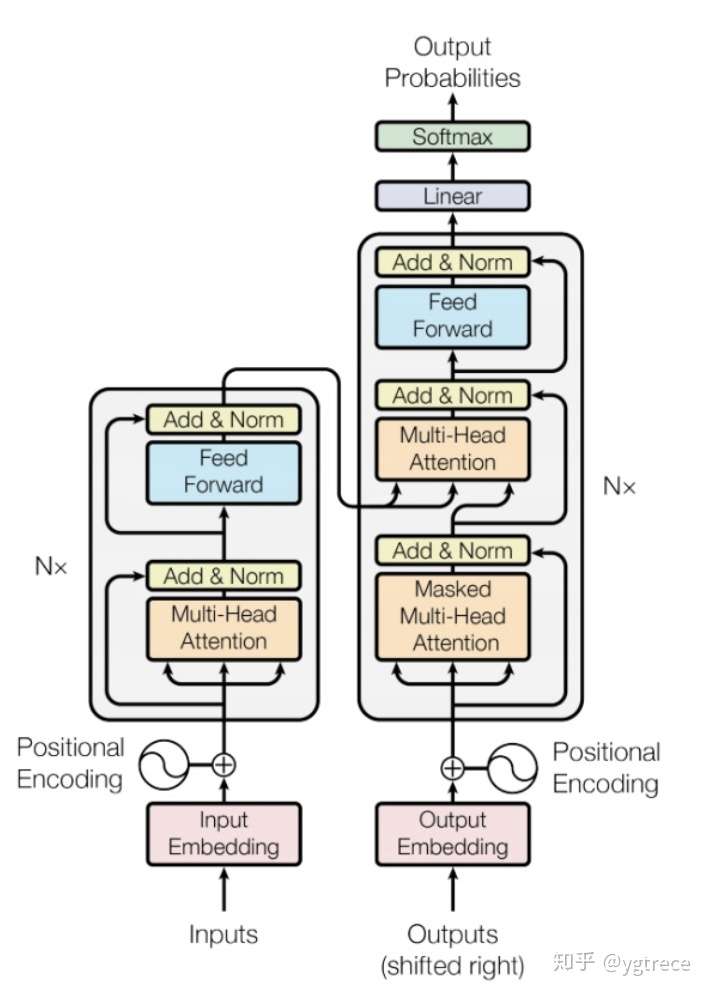
简述Transformer原理
- Positional Encoding
- Multi-Head Attention
- Residual & Layer Normalization
Scaled Dot-Product Attention为什么要scaled?(两点)
论文中解释是:向量的点积结果会很大,将softmax函数push到梯度很小的区域,scaled会缓解这种现象。怎么理解将sotfmax函数push到梯度很小区域?还有为什么scaled是维度的根号,不是其他的数?
谢邀。非常有意义的问题,我思考了好久,按照描述中的两个问题分点回答一下。
Question 1: 为什么比较大的输入会使得softmax的梯度变得很小?
对于一个输入向量 ,softmax函数将其映射/归一化到一个分布
。在这个过程中,softmax先用一个自然底数
将输入中的元素间差距先“拉大”,然后归一化为一个分布。假设某个输入
中最大的的元素下标是
,如果输入的数量级变大(每个元素都很大),那么
会非常接近1。
我们可以用一个小例子来看看 的数量级对输入最大元素对应的预测概率
的影响。假定输入
),我们来看不同量级的
产生的
有什么区别。
时,
;
时,
;
时,
(计算机精度限制)。
我们不妨把 在不同取值下,对应的的
全部绘制出来。代码如下:
from math import exp
from matplotlib import pyplot as plt
import numpy as np
f = lambda x: exp(x * 2) / (exp(x) + exp(x) + exp(x * 2))
x = np.linspace(0, 100, 100)
y_3 = [f(x_i) for x_i in x]
plt.plot(x, y_3)
plt.show()
得到的图如下所示:
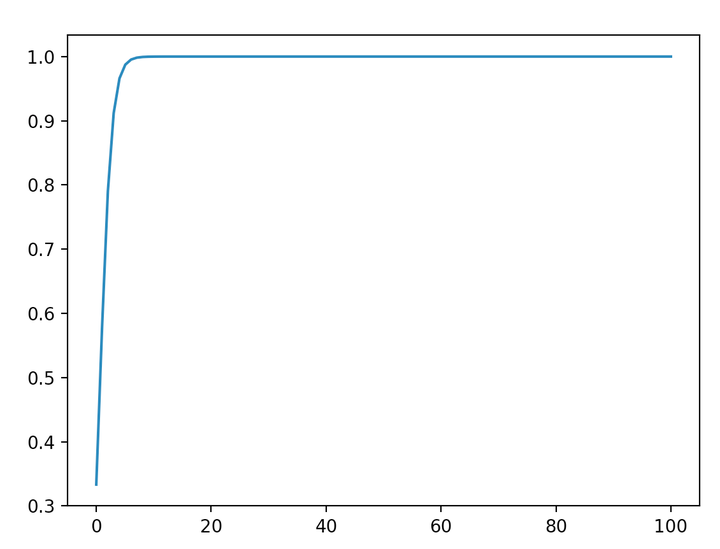
可以看到,数量级对softmax得到的分布影响非常大。在数量级较大时,softmax将几乎全部的概率分布都分配给了最大值对应的标签。
然后我们来看softmax的梯度。不妨简记softmax函数为 ,softmax得到的分布向量
对输入
的梯度为:
把这个矩阵展开:
根据前面的讨论,当输入 的元素均较大时,softmax会把大部分概率分布分配给最大的元素,假设我们的输入数量级很大,最大的元素是
,那么就将产生一个接近one-hot的向量
,此时上面的矩阵变为如下形式:
也就是说,在输入的数量级很大时,梯度消失为0,造成参数更新困难。
注: softmax的梯度可以自行推导,网络上也有很多推导可以参考。
Question 2. 维度与点积大小的关系是怎么样的,为什么使用维度的根号来放缩?
针对为什么维度会影响点积的大小,在论文的脚注中其实给出了一点解释:

假设向量 和
的各个分量是互相独立的随机变量,均值是0,方差是1,那么点积
的均值是0,方差是
。这里我给出一点更详细的推导:
对 ,
和
都是随机变量,为了方便书写,不妨记
,
。这样有:
,
。
则:
这样 ,
的均值是0,方差是1,又由期望和方差的性质, 对相互独立的分量
,有
,
以及
,
所以有 的均值
,方差
。方差越大也就说明,点积的数量级越大(以越大的概率取大值)。那么一个自然的做法就是把方差稳定到1,做法是将点积除以
,这样有:
将方差控制为1,也就有效地控制了前面提到的梯度消失的问题。
可以参考一下。水平有限,如果有误请指出。
作者:LinT
链接:https://www.zhihu.com/question/339723385/answer/782509914
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
attention和self-attention的区别
为什么self-attention可以替代seq2seq
关于为何self-attention可以代替seq2seq,论文中提到了三点:
- Complexity per layer($O(n^2 d)$)
- Sequential Operations(i.e. can be parallelized, speed-up in the training time)($O(1)$)
- Maximum Path Length(it can capture longer dependencies in a sentence.)($O(1)$)
transformer中句子的encoder表示的是什么
表示的是句子中每个token的Embedding。
怎么加入词序信息
在Word Embedding层后面加上了Positional Encoding。
Ideally, the following criteria should be satisfied:
- 唯一性。It should output a unique encoding for each time-step (word’s position in a sentence)
- 距离不变性。Distance between any two time-steps should be consistent across sentences with different lengths.
- 扩展性。Our model should generalize to longer sentences without any efforts. Its values should be bounded.
- 确定性。It must be deterministic.
在Transformer中,选择的Positional Encoding是不同频率的sine和consine函数:
参考文献:
为什么选择sinusoidal
it may allow the model to extrapolate to sequence lengths longer than the ones encountered during training.
参考文献:
BERT
BERT的具体网络结构,以及训练过程,bert为什么火,它在什么的基础上改进了些什么?
BERT是用Transformer的Encoder侧的网络,作为一个文本编码器,使用大规模数据进行预训练,预训练使用两个loss:
- 一个是Masked LM,遮蔽掉源端的一些字(可能会被问到mask的具体做法,15%概率mask词,这其中80%用[mask]替换,10%随机替换一个其他字,10%不替换,至于为什么这么做,那就得问问BERT的作者了),然后根据上下文去预测这些字;
- 一个是Next Sentence Prediction,判断两个句子是否在文章中互为上下句,然后使用了大规模的语料去预训练。
在它之前是GPT,GPT是一个单向语言模型的预训练过程(它和GPT的区别就是bert为啥叫双向 bi-directional),更适用于文本生成,通过前文去预测当前的字。下图为transformer的结构,bert的网络结构则用了左边的encoder。
为什么BERT有3个嵌入层,它们都是如何实现的
本文将阐述BERT中嵌入层的实现细节,包括token embeddings、segment embeddings, 和position embeddings.
下面这幅来自原论文的图清晰地展示了BERT中每一个嵌入层的作用:
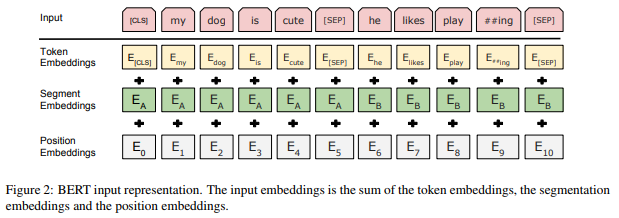
和大多数NLP深度学习模型一样,BERT将输入文本中的每一个词(token)送入token embedding层从而将每一个词转换成向量形式。但不同于其他模型的是,BERT又多了两个嵌入层,即segment embeddings和 position embeddings。在阅读完本文之后,你就会明白为何要多加这两个嵌入层了。
Token Embeddings
作用
正如前面提到的,token embedding 层是要将各个词转换成固定维度的向量。在BERT中,每个词会被转换成768维的向量表示。
实现
假设输入文本是 “I like strawberries”。下面这个图展示了 Token Embeddings 层的实现过程:

输入文本在送入token embeddings 层之前要先进行tokenization处理。此外,两个特殊的token会被插入到tokenization的结果的开头 ([CLS])和结尾 ([SEP]) 。它们视为后面的分类任务和划分句子对服务的。
tokenization使用的方法是WordPiece tokenization. 这是一个数据驱动式的tokenization方法,旨在权衡词典大小和oov词的个数。这种方法把例子中的“strawberries”切分成了“straw” 和“berries”。这种方法的详细内容不在本文的范围内。有兴趣的读者可以参阅 Wu et al. (2016) 和 Schuster & Nakajima (2012)。使用WordPiece tokenization让BERT在处理英文文本的时候仅需要存储30,522 个词,而且很少遇到oov的词。
Token Embeddings 层会将每一个wordpiece token转换成768维的向量。这样,例子中的6个token就被转换成了一个(6, 768) 的矩阵或者是(1, 6, 768)的张量(如果考虑batch_size的话)。
Segment Embeddings
作用
BERT 能够处理对输入句子对的分类任务。这类任务就像判断两个文本是否是语义相似的。句子对中的两个句子被简单的拼接在一起后送入到模型中。那BERT如何去区分一个句子对中的两个句子呢?答案就是segment embeddings.
实现
假设有这样一对句子 (“I like cats”, “I like dogs”)。下面的图成仙了segment embeddings如何帮助BERT区分两个句子:
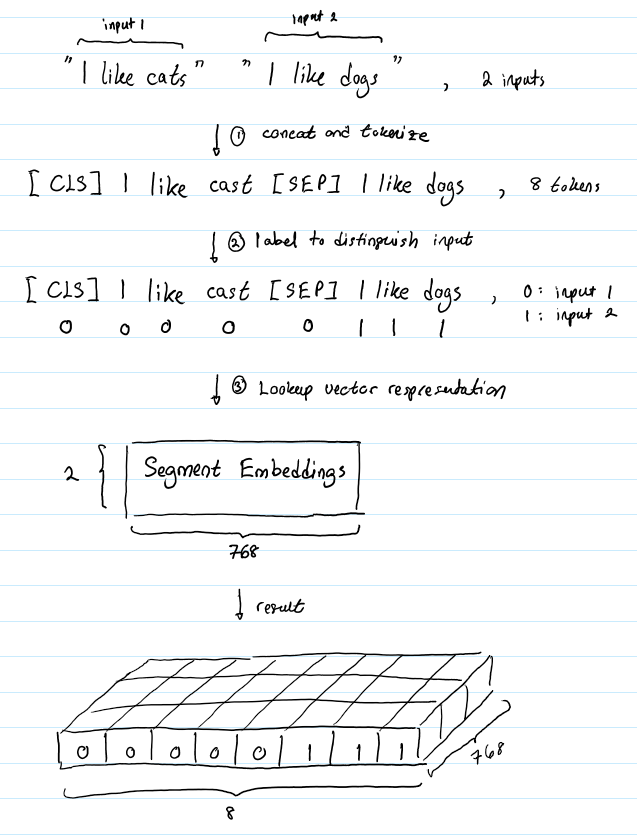
Segment Embeddings 层只有两种向量表示。前一个向量是把0赋给第一个句子中的各个token, 后一个向量是把1赋给第二个句子中的各个token。如果输入仅仅只有一个句子,那么它的segment embedding就是全0。
Position Embeddings
作用
BERT包含这一串Transformers (Vaswani et al. 2017),而且一般认为,Transformers无法编码输入的序列的顺序性。 博客更加详细的解释了这一问题。总的来说,加入position embeddings会让BERT理解下面这种情况:
I think, therefore I am
第一个 “I” 和第二个 “I”应该有着不同的向量表示。
实现
BERT能够处理最长512个token的输入序列。论文作者通过让BERT在各个位置上学习一个向量表示来讲序列顺序的信息编码进来。这意味着Position Embeddings layer 实际上就是一个大小为 (512, 768) 的lookup表,表的第一行是代表第一个序列的第一个位置,第二行代表序列的第二个位置,以此类推。因此,如果有这样两个句子“Hello world” 和“Hi there”, “Hello” 和“Hi”会由完全相同的position embeddings,因为他们都是句子的第一个词。同理,“world” 和“there”也会有相同的position embedding。
合成表示
我们已经介绍了长度为n的输入序列将获得的三种不同的向量表示,分别是:
- Token Embeddings, (1, n, 768) ,词的向量表示
- Segment Embeddings, (1, n, 768),辅助BERT区别句子对中的两个句子的向量表示
- Position Embeddings ,(1, n, 768) ,让BERT学习到输入的顺序属性
这些表示会被按元素相加,得到一个大小为(1, n, 768)的合成表示。这一表示就是BERT编码层的输入了。
BERT为什么使用position embedding而不是position encoding?

讲讲multi-head attention的具体结构
BERT-BASE由12层transformer layer(encoder端)构成,首先token embedding , postion embedding(可能会被问到有哪几种position embedding的方式,bert是使用的哪种), segment embedding做加和作为网络输入,每层由一个multi-head attention, 一个feed forward 以及两层layerNorm构成,一般会被问到multi-head attention的结构,具体可以描述为:
step 1:
一个768的hidden向量,被映射成query, key, value。 然后三个向量分别切分成12个小的64维的向量,每一组小向量之间做attention。不妨假设batch_size为32,seqlen为512,隐层维度为768,12个head。
hidden(32 x 512 x 768) -> query(32 x 512 x 768) -> 32 x 12 x 512 x 64
hidden(32 x 512 x 768) -> key(32 x 512 x 768) -> 32 x 12 x 512 x 64
hidden(32 x 512 x 768) -> val(32 x 512 x 768) -> 32 x 12 x 512 x 64
step 2:
然后query和key之间做attention,得到一个32 x 12 x 512 x 512的权重矩阵,然后根据这个权重矩阵加权value中切分好的向量,得到一个32 x 12 x 512 x 64 的向量,拉平输出为768向量。
32 x 12 x 512 x 64(query_hidden) * 32 x 12 x 64 x 512(key_hidden) -> 32 x 12 x 512 x 512
32 x 12 x 64 x 512(value_hidden) * 32 x 12 x 512 x 512 (权重矩阵) -> 32 x 12 x 512 x 64
然后再还原成 -> 32 x 512 x 768
简言之是12个头,每个头都是一个64维度分别去与其他的所有位置的hidden embedding做attention然后再合并还原。
BERT 采用哪种Normalization结构,LayerNorm和BatchNorm区别,LayerNorm结构有参数吗,参数的作用?
采用LayerNorm结构,和BatchNorm的区别主要是做Normalization的维度不同;
BatchNorm针对一个batch里面的所有样本进行规范化,针对单个神经元进行,比如batch里面有64个样本,那么规范化输入的这64个样本各自经过这个神经元后的值(64维)。
LayerNorm则是针对单个样本,不依赖于其他数据,常被用于小mini-batch场景、动态网络场景和 RNN,特别是自然语言处理领域,就BERT来说就是对每层输出的隐层向量(768维)做规范化。
图像领域用BN比较多的原因是因为每一个卷积核的参数在不同位置的神经元当中是共享的,因此也应该被一起规范化。
class BertLayerNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-5):
super(BertLayerNorm, self).__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.bias = nn.Parameter(torch.zeros(hidden_size))
self.variance_epsilon = eps
def forward(self, x):
u = x.mean(-1, keepdim=True)
s = (x - u).pow(2).mean(-1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.variance_epsilon)
return self.weight * x + self.bias
贴一个LayerNorm的实现,可以看到module中有weight和bias参数,以Sigmoid激活函数为例,批量归一化之后数据整体处于函数的非饱和区域, 只包含线性变换,破坏了之前学习到的特征分布。为了恢复原始数据分布,具体实现中引入了变换重构以及可学习参数w和b ,也就是上面的weight和bias,简而言之,规范化后的隐层表示将输入数据限制到了一个全局统一的确定范围,为了保证模型的表达能力不因为规范化而下降,引入了是再平移参数,
是再缩放参数。(过激活函数前规范化,之后还原)
我认为BN效果不好的原因,主要还是NLP数据与CV数据特性的差别对训练过程产生了影响,使得训练中batch的统计量不稳定。



