Joint Extraction of Entities and Relations Based on a Novel Decomposition Strategy
Background
- Joint Extraction of Entities and Relations 是指用一个model来检测句子中的entity pair以及entity pair之间的relation。以往的method通常采用extract-then-classify或者是unified labeling manner来求解。这些方案会带来很多冗余的entity pairs以及忽视了实体抽取和关系抽取的内在联系;
- 如果一个模型不能完全感知head entity的语义,那么提取相应的尾实体和关系就不可靠;
Contributions
- 为了解决Background中的问题,本文将joint extraction拆解成两个子任务——Head-Entity Extraction和Tail-Entity Relation Extraction。这是一种extract-then-label的方法,能够减少冗余的entity pair。
- HE 和 TER extraction采用的是相同的span-based extraction framework。HE子任务用于抽取出一个句子中所有可能的Head-Entities,TER子任务则是对于每个Head -Entity,抽取出其对应的Tail-Entity和Relation。
- TER能够充分利用head-entity的语义和位置信息。
Terminology/Related Work
Overlapping Relation
multiple relations share a common entity.
Pipeline Relation Extraction
Traditional pipelined methods divide this task into two separate subtasks: first extract the token spans in the text to detect entity mentions, and then discover the relational structures between entity mentions.
先用一个model进行实体识别,再用另一个model寻找实体对之间的关系。这种方式忽略了子任务之间的内在联系,存在error propagation。解决的办法之一就是通过parameter sharing来进行联合训练。[4, 17, 23]
Joint Relation Extraction
extraction-then-classify
这种先提取后分类的方法虽然有了joint loss,但是仍然需要不同的独立组件来分别进行实体提取和关系分类。
extraction-then-label
本文提出的方法,对于HE和TER采用相同的HBT。
Framework/Method
Tagging Scheme
Sequence Labeling Task有很多不同的tagging schemes,例如BIO,BIEOS,span-based等等。本论文采用的是span-based的tagging schemes。

如上图所示。首先看看 head-entity extraction,它被分解成两个sequence labeling subtasks。第一个subtask用于识别the start of head-entities,第二个subtask用于识别the end of head-entities。
接着,对于每一个head-entity,TER extraction同样被分解为两个sequence labeling subtasks来识别start和end。
这种tagging scheme的优势在于对于有m个head-entities的句子,整个任务被解构为2 + 2m个序列标记子任务,前2个为HE标记子任务,另外2m为TER标记子任务。比以往的论文有优势。
Hierarchical Boundary Tagger
所谓层次的含义是start tagger和end tagger,它们两个是有先后顺序的。
上节介绍了tagging scheme,这是模型的输出,那么怎么得到这种输出呢?论文中使用了一个unified hierarchical boundary tagger(HBT)。由于HE和TER采用的都是HBT,所以下面的讲解不进行区分。
对于从一个句子$S$抽取一个标签为$l$的目标$t$,其概率可以描述为如下:
$$
p(t,l|S) = p(s_t^l|S)p(e_t^l|s_t^l,S) \tag{1}
$$
这样一种decomposition strategy说明:在抽取目标的时候,start的抽取结果会影响到end的抽取结果。这也就是使用HBT的motivation。

假设现在进行start tag,那么标注单词$x_i$的公式如下:

其中$\mathbf{a}_i$是一个笼统的概念——auxiliary vector。对于HE extraction,它是上图中的$g$,代表a global representation learned from the entire sentence。对于TER extraction,它是$g$,$h^h$和$P_i^{ht}$的组合。
同理,在进行end tag的时候,公式如下:

start tag(公式2-4)和end tag(公式5-7)的区别在于:
我们用$\mathbf{h}_i^{sta}$代替了$\mathbf{h}_i$,这样就能够在进行end tag的时候嵌入start tag的信息;
增加了一个$\mathbf{p}_i^{se}$作为一个单词${word}_i$距离最近的一个start position的距离:

嵌入这种信息,是因为我们希望模型能够限制提取的实体的长度,并学习到结束位置不可能在开始位置之前。
训练时(training),采用cross entropy来作为损失函数:

在推断阶段(inference),解码方式采用的是——**multi-span decoding algorithm**:

EXTRACTION SYSTEM
上面是对模型的创新之处——tagging scheme和hierarchical boundary tagger两个方面讲起。接下来,将从Figure 2中揭示的模型整体结构来看看。
Shared Encoder
共享编码层,这是joint方法的常见操作:

HE Extractor
HE Extractor用于识别候选的head-entities。计算公式如下:

其中$\mathbf{R}{HE} = { (h_j , type{h_j}) }_{j=1}^{m}$。
TER Extractor
TER Extractor是要以Head Entity为前提的,因此我们的模型输入应该要能够包含Head Entity的信息最好,那么怎么包含呢?论文提出了两方面的信息:
- 加入head entity的特征;
- 加入${word}_i$到head entity的距离信息;
综上,得到下面的公式:

其中$\mathbf{h}^h = [\mathbf{h}{s_h};\mathbf{h}{e_h};]$。$\mathbf{p}_i^{ht}$就是position embedding(负数embedding怎么查找呀?一个head entity要是一个span怎么计算距离呢?)。
接下来就是:

其中,

最后,我们将head entity和tail entity,relation结合在一起,就得到了最后的关系抽取三元组——${ (h, rel_o,t_o) }_{o=1}^{z}$。需要特别注意的是,在训练的过程中,$h$使用的是gold head-entity,只是在inference阶段,才会用HE模块得到的head entity。
Training of Joint Extractor
一直困扰我的就是joint model是怎么训练的,看了这个论文,我大概知道了,原来也没有那么复杂。
问题主要出在TER extractor的输入上,论文中说到,虽然HE extractor抽取了所有的head entity,但是TER extraction的输入只有一个head entity!如果想要遍历所有的head entity,那么需要以head entity为单位生成新的数据:
To share input utterance across tasks and train them jointly, for each training instance, we randomly select one head-entity from gold head-entity set as the specified input of the TER extractor. We can also repeat each sentence many times to ensure all triplets are utilized,
but the experimental results show that this is not beneficial.
综上所述,joint loss如下:

Experiments
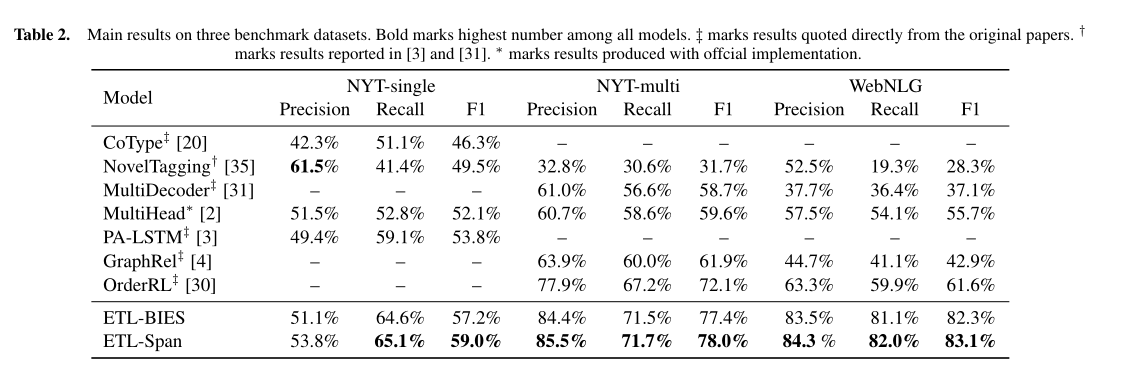
实验结果:
代码地址
https://github.com/yubowen-ph/JointER
Thinking/Further Work
论文:
- Suncong Zheng, Feng Wang, Hongyun Bao, Yuexing Hao, Peng Zhou, and Bo Xu, ‘Joint extraction of entities and relations based on a novel tagging scheme’, in Proc. of ACL, pp. 1227–1236, (2017).
- Changzhi Sun, Yuanbin Wu, Man Lan, Shiliang Sun, Wenting Wang, Kuang-Chih Lee, and Kewen Wu, ‘Extracting entities and relations with joint minimum risk training’, in Proc. of EMNLP, pp. 2256–2265, (2018).
- Minjoon Seo, Aniruddha Kembhavi, Ali Farhadi, and Hannaneh Hajishirzi, ‘Bidirectional attention flow for machine comprehension’, arXiv preprint arXiv:1611.01603, (2016).
- https://kexue.fm/archives/6671
- https://blog.csdn.net/qq_38556984/article/details/109092842



