A Closer Look At Few-Shot Classification
@article{chen2019closer,
title={A closer look at few-shot classification},
author={Chen, Wei-Yu and Liu, Yen-Cheng and Kira, Zsolt and Wang, Yu-Chiang Frank and Huang, Jia-Bin},
journal={arXiv preprint arXiv:1904.04232},
year={2019}
}
一、文章针对的问题和主要贡献
在小样本学习(Few-shot Learning)方面,近几年各种方法层出不穷,模型结构和学习算法也越来越复杂。然而,这些方法之间没有在统一的框架下进行比较。这篇文章针对几个关键问题,如数据集对小样本学习方法的影响、网络深度对这些方法的性能的影响以及领域漂移下这些方法的表现,对当前的小样本学习方法进行性能比较和阐释。具体地,本文有以下三个主要贡献:
- 对已有的representative few-shot classification algorithms做了比较。特别地,实验了基础模型(
backbone)的能力对这些方法的性能的影响,结果显示,在领域差异比较小的情况下(如CUB这种细粒度(fine-grained)分类任务),随着基础即特征提取神经网络的能力的提高(从四层的CNN提升到resnet),这些方法之间的性能差异越来越小;相反地,在领域差异比较大的情况下(如miniImageNet),随着基础即特征提取神经网络的能力的提高,这些方法的性能差异越来越大; - 文章建立了两个普通简单的baseline,发现在CUB和miniImageNet上的性能足以和当前最先进的基于元学习的方法媲美;
- 基于(1)的结果和一些已有的研究,作者特别强调了小样本学习任务中的领域自适应问题,并且设计实验显示当前这些state-of-the-art的小样本学习方法在领域漂移的情况下表现相当不好,没有baseline表现好,提醒人们对这个方向多关注。
二、模型介绍
Baseline and Baseline++
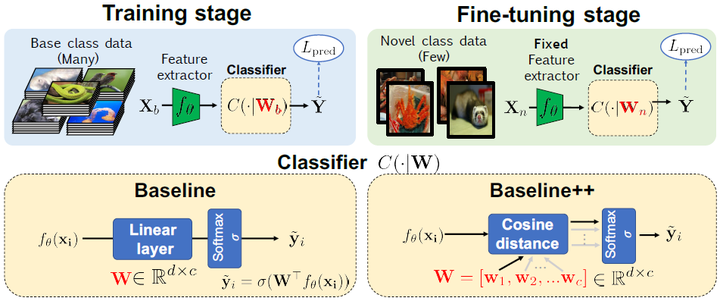
上图就是本文提出的模型。
其中包括baseline和baseline++模型,两个模型都是采用标准的transfer learning学习方法——pre-training和finetuning。
它们都包括两个阶段Training stage和Fine-tuning stage:
- Training stage:输入是base dataset,作用是得到$f(\theta)$用来抽取特征。
- Finetuning stage:输入是support set,作用是得到一个用于novel class之上的classifier。
论文中没有提到的是——通常support set很小,因此在finetuning的时候,需要加入regularization来防止过拟合。(参考王树森老师的lecture中提到的论文——A baseline for few-shot image classification)
baseline在分类时使用了线性分类器(即Linear Layer);baseline++在分类时使用了cos距离(cosine distance)的分类器,论文作者提出cosine distance能够降低intra-class variations(好像只要是distance就可以降低intra-class variations,而且$W$里面的向量也可以看作是每个类别的prototype)。
下图显示了本文比较的四个基于meta-learning模型,分别是MatchingNet,ProtoNet,RelationNet,MAML:
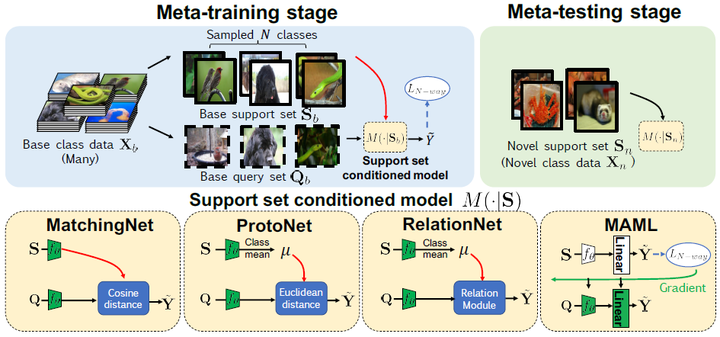
如上图所示,基于meta-learning的方式通常包括两个阶段:meat-training stage和meta-testing stage,这与前文提到的baseline和baseline++有所不同。
三、实验
(1) Evaluation Using The Standard Setting
所谓的standard setting就是few-shot论文中常见的evaluation setting,直接看下面这张表就是了:

(2) Effect Of Increasing The Network Depth
如下图所示,结果显示:
- 在领域差异比较小的情况下,随着基础即特征提取神经网络的能力的提高(从四层的CNN提升到resnet),这些方法之间的性能差异越来越小;
- 相反地,在领域差异比较大的情况下,随着基础即特征提取神经网络的能力的提高,这些方法的性能差异越来越大。

(3) Effect Of Domain Differences Between Base And Novel Classes
state-of-the-art的小样本学习方法在**领域漂移(domain shift)**的情况下表现相当不好,没有baseline表现好

四、总结
本文没有提出什么先进的模型,但是却进行了一些有意义的实验,提出了几个大家容易忽略的问题,对小样本分类这一问题有了更加深刻的认识,也指出了一些存在的问题,因此是比较有价值的。特别地,文章强调了特征提取网络(即backbone)的能力、数据集的差异性以及领域自适应问题对小样本学习任务的影响,特别强调了应该关注小样本学习中的领域自适应问题。不过在这篇文章的评审过程中,有审稿人觉得领域自适应不应该在小样本学习任务中强调,但是作者坚持自己的看法。
这一研究也启示我们在研究过程中应该全面考虑问题,自己得到的模型性能也很大程度上受限于数据集、基础模型等问题的影响,在其他条件下,可能最简单的模型最具有竞争力。
阅读这篇文章的主要原因是我毕业设计用的few-shot方法就是这篇论文中说到的pre-training和finetuning的,想读文章更加深入了解一下这种方法。



