Span-based Joint Entity and Relation Extraction with Transformer Pre-training
发表在ECAI 2020上的一篇文章。
Background(要解决的问题)
- 传统的BIO/BILOU等序列标注方式不能很好地解决重叠实体的问题,例如实体
codeine被实体codeine intoxication所包含; - 进行关系抽取时,大多的方法没有应用到实体与实体之间相隔的局部上下文关系。
Contributions(创新点)
- 抛弃了传统的BIO/BILOU标注实体的方式,构建了一个完全基于跨度的联合实体识别和关系抽取模型——SpBERT;
- 使用了负采样的方式增强模型;
- 通过max pooling的方式,提取了一个关系中实体对之间的文本特征;
Method
0. An Example of the Method(Overview)

如上图所示,模型主要由span classification,span filtering,relation classification三个部分构成。其中span classification和span filtering用于实体的识别和分类,relation classification用于关系抽取。
1. Span Classification
通过BERT之后,模型获得了句子的向量表示:$(c,e_1,e_2,…,e_n)$。之后模型将在任意的跨度(即span)内判断其是否为实体。例如,对于句子(we,will,rock,you),将要检测(we),(we will),(rock,you)等等跨度是否为实体。在实现阶段,模型不会对所有的实体和关系进行beam search,而是通过positive entity span + negative sampling的方式构建训练集,具体来说是:使用所有标注为实体的跨度$S^{gt}$作为正样本,同时从不是实体的跨度中,只随机抽取其中的$N_e$个作为负样本。
如上图所示,Span Classifier的输入包含三个部分:跨度的向量表示(红色),宽度嵌入(蓝色),CLS的向量表示(绿色)。
其中,跨度的向量表示是通过max pooling操作得来的。宽度嵌入的含义是不同的跨度宽度,所表达的信息是不一样的,因此需要加入到特征中。CLS的向量表示用于提供语境上下文的信息。
最后,过一个线性分类层就可以得到跨度对应的实体类型了:
$$
{\bf {\hat y}} ^s = softmax(W^s \cdot {\bf x}^s + b)
$$
2. Span Filtering
这个步骤是衔接Span Classification和Relation Classification,功能很简单,就是剔除Span Classification中预测不是实体的跨度,将是实体的跨度输入到Relation Classification之中。
3. Relation Classification
在上一步中,我们得到了所有预测为实体的跨度,接下来就是预测它们之间的关系,与Span Classification相似,这里同样使用positive relation + negative sampling的方式,具体来说就是:使用所有标注为存在关系的entity pair作为正样本,其他不存在关系的entity pair中,我们随机采样$N_r$个作为负样本。
如上图所示,Relation Classification的输入包含三个部分:$Entity_i$的特征向量,$Entity_i$和$Entity_j$之间的local context的特征向量,以及$Entity_j$的特征向量。
最后将其输入到一个多标签的线性分类器(而不是多分类)中:
$$
{\bf \hat y_{1/2}} := \sigma(W^r \cdot x^r_{1/2} + b^r)
$$
因为关系是非对称的,所以要分开识别$(Entity_i,Entity_j)$和$(Entity_j,Entity_i)$。
最后的损失函数就是常见的Joint损失函数:
$$
\mathcal L = \mathcal L^s + \mathcal L^r
$$
Experiments
作者在三个数据集:CoNLL04,SciERC,ADE上进行了实验,得到的结果都是SOTA:

后记
思考
这篇文章的思路其实也很简单,但是结果却是很有效的。其改进了上篇文章中会存在的overlapping entity的问题。
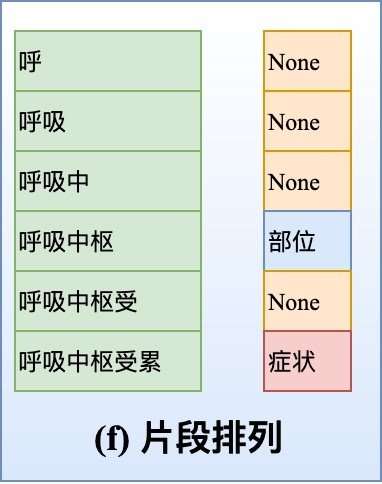
同时,它的思想更像是一种非常暴力地枚举每个可能的span,然后一一进行判断,假设一个句子有$N$个token,那么理论上需要判断的span有$N \cdot (N+1) /2$,计算量应该会很大,好在其在训练时,提出了有效的negative sampling技术,保证了计算量不会太大。下图是我在知乎文章中看到的更加形象的描述图:
后续阅读
- Entity, Relation, and Event Extraction with Contextualized Span Representations
- Empirical Analysis of Unlabeled Entity Problem in Named Entity Recognition



